Ollama : Installez LLama 2 et Code LLama en quelques secondes !
L'actualité des LLM ou Large Language Models s'enflamme depuis le lancement de ChatGPT il y a à peine un an.
Depuis Meta, la maison mère de Facebook, a diffusé il y a quelques mois des modèles Opensource capables de concurrencer les modèles d'OpenAI utilisés par ChatGPT. La dernière version en date est LLama 2 publiée officiellement le 24 Août dernier et qui est disponible en 3 formats différents: 7B, 13B et 34B. Mais il existe aussi de nombreux "forks" sur Huggingface.
Vous allez me demander à quoi correspondent ces chiffres. Il s'agit du nombre de paramètres au sein du modèle. Plus ce nombre est grand, plus il est en mesure de traiter des tâches complexes, plus il consomme de la mémoire RAM et plus il peut être lent ...
Sur des ordinateurs équipés de GPU, il aujourd'hui est possible de faire fonctionner des modèles LLama 7B si vous disposez des 16Go de RAM et des modèles 13B si vous disposez des 32Go de RAM. C'est par exemple le cas des Mac Book pro M2, ils peuvent facilement exécuter un modèle 7B avec des performances acceptables (40 tokens / seconde).
Comment installer ces modèles sur votre ordinateur ?
Pour vous faire gagner du temps, il existe un petit logiciel disponible sur Mac/Linux et bientôt sous Windows qui se prénomme Ollama. Celui-ci vous permet de charger rapidement des modèles et de les faire fonctionner en fond de tâche sur son ordinateur.
Son utilisation est très simple, après avoir téléchargé et installé Ollama, il vous suffit de lancer la commande suivante pour télécharger le modèle llama2.
$ ollama pull llama2
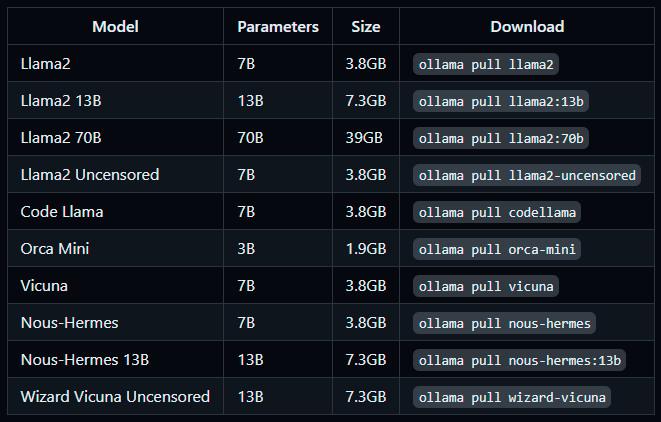
Voici les autres modèles téléchargeables au travers de la commande pull :
La commande suivante vous permet de démarrer le modèle sous forme d'un webservice interrogeable sur le port 11434 de votre ordinateur.
$ ollama serve llama2
Comment requêter le modèle ?
Pour le requêter, vous pouvez tout simplement utiliser la commande suivante :
ollama run llama2 'tell me a joke'
Vous pouvez aussi intéroger le modèle au travers de son Webservice exposé sur le port 11434 de l'ordinateur :
curl -X POST https://localhost:11434/api/generate -d '{
"model": "llama2",
"prompt":"Pourquoi le ciel est bleu ? "
}'
Par défaut Ollama expose un port sur le localhost de la machine, il est possible de spécifier l'interface réseau d'écoute en définissant la variable système : OLLAMA_HOST
OLLAMA_HOST=123.1.1.1 ollama serve
Sous Linux, cela peut être réalisé facilement en modifiant le fichier Systemd permettant de démarrer le processus Ollama comme daemon.
echo 'Environment="OLLAMA_HOST=0.0.0.0:11434"' >>/etc/systemd/system/ollama.service.d/environment.conf
Et Code LLama dans tout cela ?
Si vous souhaitez plutôt poser des questions techniques autour du développement informatique, vous pouvez utiliser le modèle Code LLama qui a été entrainé spécifiquement pour ce genre d'exercice.
$ ollama pull codellama
$ ollama serve codellama
Si vous êtes développeur, vous pouvez ensuite intégrer CodeLLama directement dans VSCode au travers du plugin Continue.
Ou au travers du plugin LLama Coder qui offre une fonctionnalité d'autocomplétion de code très intéressante alternative à Github Copilot.
D'autres idées d'intégration
Si vous utilisez Obsidian gestionnaire de notes, il existe une extension capable d'intégrer Ollama pour générer du texte.
De nombreux autres intégrations sont possibles grâce à l'écosystème grandissant de Ollama. La liste exhaustive est disponible sur la page Github Ollama.