
J'ai reçu un PDF avec une vulnérabilité Zero day ?
Suite à la quantité de vulnérabilités zéro day exploitées sur le lecteur PDF Adobe Reader, je ne donne plus aucune confiance aux fichiers PDF reçus par email ou trouvés sur le Web.
J'ai très récemment reçu plusieurs emails faisant de la publicité pour la marque Boulanger et ressemblant à de l'hameçonnage. Les emails provenaient d'un domaine Firebase hébergé Google.
Ces emails contenaient un contenu m'indiquant le gain d'un lot dans lequel était adjoint un PDF vraiment très étrange.
Après avoir analysé ces fichiers avec la plateforme VirusTotal, ceux-ci semblent contenir aucune vulnérabilité connue. L'ensemble des antivirus attachés à la plateforme VirusTotal n'ont rien trouvé de convaincant.
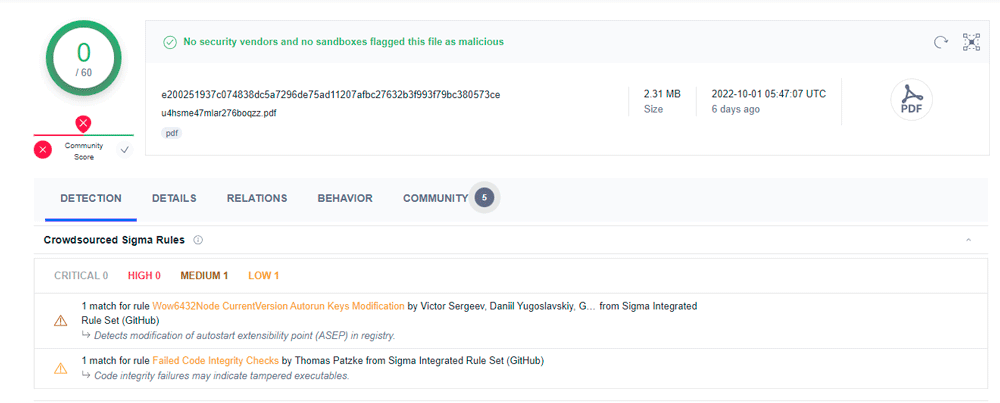
Je ne suis à priori pas le seul à avoir analysé le contenu du fichier, mais je reste étonné que personne n'ait remonté un éventuel problème.
En investiguant le contenu du PDF avec l'outil pdf-parser disponible sur Kali Linux, on se rend compte que le fichier contient pas moins de 5083 commentaires et absolument rien d'autre. Mes soupçons se confirment.
$ pdf-parser -a u4hsme47mlar276boqzz.pdf
Comment: 5083
XREF: 0
Trailer: 0
StartXref: 0
Indirect object: 0
En analysant maintenant le contenu des commentaires, ceux-ci sont constitués uniquement de caractères en hexadécimal.
PDF Comment '%\xbd\xda7\x0b\n'
Contre toute attente, chaque ligne de commentaire se termine soit par un "\n" ou un "\r".
En détaillant le contenu du PDF, les 5083 commentaires sont en fait 130 lignes de commentaires répété plusieurs fois au sein du fichier.
Nom de Zeus ! Cela ressemble très fortement à une attaque de type Buffer Overflow autour de l'interprétation des caractères "Cariage return" ou je me trompe ?
Les caractères en hexadécimal ne seraient-ils pas tout simplement de l'assembleur ?
Petit passage sur le Discord Geeek, je demande à la communauté sur le canal #cybersecurité pour avoir un avis. Spawnrider lance une analyse avec Capstone.
L'extraction des commentaires du PDF produit un résultat plutôt intéressant qui pourrait confirmer qu'il s'agit bien d'une attaque utilisant l'exploitation d'un buffer overflow :
0x0: pop esp
0x1: js 0x64
0x3: aaa
0x4: pop esp
0x5: js 0x69
0x7: xor eax, 0x3964785c
0xc: pop esp
0xd: js 0x73
0xf: aaa
0x10: pop esp
0x11: js 0x76
0x13: xor byte ptr [edi + 0x5c], dl
0x16: js 0x7b
0x18: pop esp
0x1a: js 0x4c
0x1c: cmp byte ptr [ecx + 0x5c], ch
0x1f: js 0x52
0x21: xor eax, 0x66785c20
0x26: bound ebx, qword ptr [eax + edi*2 + 0x38]
0x2a: cmp byte ptr [eax + edi*2 + 0x65], bl
0x2e: cmp dword ptr [eax + edi*2 + 0x38], ebx
0x32: bound ebx, qword ptr [eax + edi*2 + 0x62]
0x36: pop esp
0x38: js 0x6b
0x3a: cmp dword ptr [eax + edi*2 + 0x39], ebx
0x3e: cmp dword ptr [ecx + 0x2a], esi
0x41: pop esp
0x42: js 0x7d
0x44: cmp dword ptr [edx + 0x5c], eax
0x47: js 0xac
0x49: pop sp
0x4b: js 0xb1
0x4d: sub al, 0x5c
0x50: js 0xb6
0x52: pop esp
0x54: js 0xbc
0x56: xor bl, byte ptr [eax + edi*2 + 0x66]
0x5a: xor bl, byte ptr [eax + edi*2 + 0x39]
0x5e: xor dword ptr [esp + ebx*2 + 0x5c], ebx
0x62: js 0xc5
0x64: pop esp
0x66: js 0xca
0x68: popal
Il reste maintenant à comprendre quel lecteur de PDF est ciblé. S'agit-il d'Adobe Reader, de Edge ou bien d'un lecteur PDF sur Android ou iOS ?
Pourquoi le fichier n'est pas détecté par un Antivirus ?
Que se produit-il sur le périphérique vulnérable une fois le fichier ouvert ?
Je n'irai pas plus loin dans l'analyse cette fois-ci, si vous avez des compétences en assembleur, le fichier est disponible tout en bas de l'article. En attendant, faites très attention aux PDF que vous recevez ! N'ouvrez aucun fichier transmis par un inconnu.
Pour continuer la discussion, rejoignez le canal #cybersécurité sur le serveur Discord Geeek.

