
Comment bloquer les Robots qui aspirent le contenu de votre site pour entraîner des modèles LLM ?
Votre site Web se fait régulièrement aspirer son contenu par des robots spécialisés dans la production de modèles LLM (Large Language Model) tels que OpenAI, Perplexity, Claude, etc.
Ce phénomène peut entraîner une consommation importante de ressources sur votre hébergement et vous pourriez ne pas souhaiter que votre contenu soit exploité pour produire des LLM commerciaux sans votre consentement.
D'après l'étude réalisée par Cloudflare, ce traffic illégitime est en pleine croissance sur ces derniers mois. Les deux bots les plus verbeux étant Bytespider de la firme chinoise gérant TikTok et GPTBot d'OpenAI :
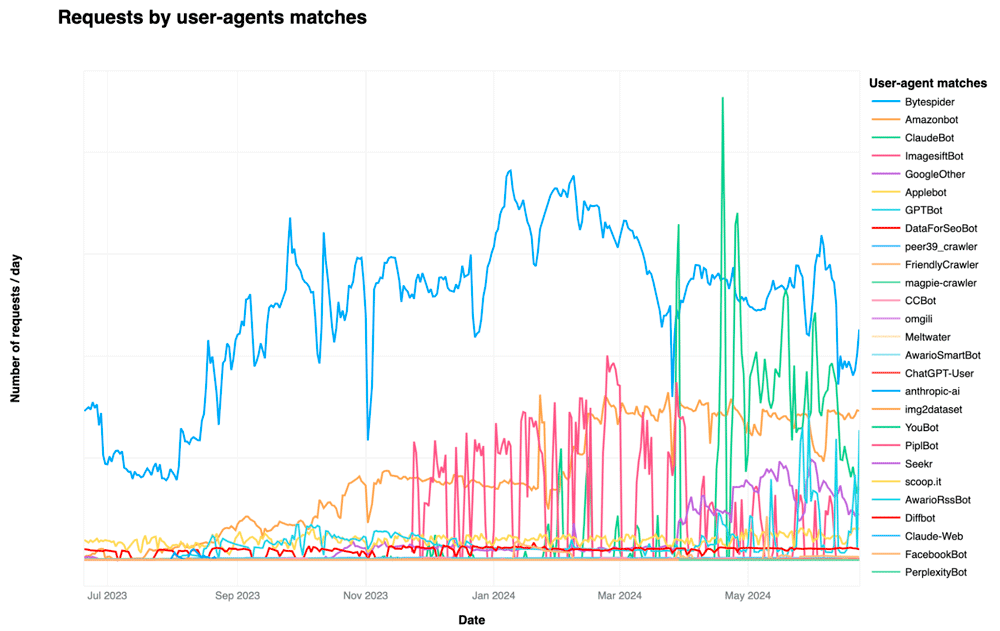
(source : Cloudflare)
Heureusement, il existe des solutions pour protéger votre site contre ces robots.
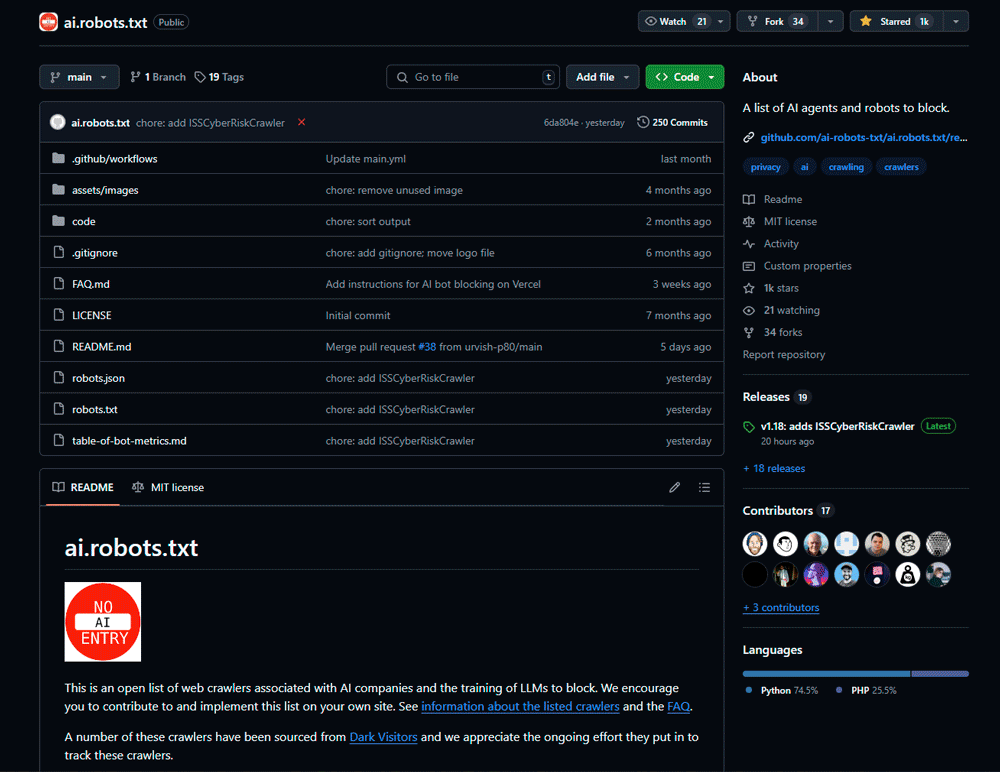
Présentation du projet ai.robots.txt
ai.robots.txt est un projet open-source disponible sur GitHub qui a comme objectif d'identifier et de lister l'ensemble des user-agents des robots associés aux sociétés qui produisent des LLM.
Cette liste évolue en permanence en fonction des nouveaux robots identifiés sur la toile.
Méthode 1 : Bloquer l'indexation de votre site Web via le fichier robots.txt
Le fichier robots.txt permet de donner des directives aux robots d'indexation sur les pages qu'ils peuvent ou ne peuvent pas explorer.
Étapes :
- Téléchargez le contenu du fichier robots.txt depuis le projet ai.robots.txt.
- Ajoutez ou fusionnez ce contenu avec le fichier robots.txt de votre site Web.
Cela n'effacera pas les contenus déjà récupérés par ces robots, mais cela les informera de ne pas indexer de nouveaux contenus.
Exemple de fichier Robots.txt :
User-agent: AI2Bot
User-agent: Ai2Bot-Dolma
User-agent: Amazonbot
User-agent: Applebot
User-agent: Applebot-Extended
User-agent: Bytespider
User-agent: CCBot
User-agent: ChatGPT-User
User-agent: Claude-Web
User-agent: ClaudeBot
User-agent: Diffbot
User-agent: FacebookBot
User-agent: FriendlyCrawler
User-agent: GPTBot
User-agent: Google-Extended
User-agent: GoogleOther
User-agent: GoogleOther-Image
User-agent: GoogleOther-Video
User-agent: ICC-Crawler
User-agent: ImagesiftBot
User-agent: Kangaroo Bot
User-agent: Meta-ExternalAgent
User-agent: Meta-ExternalFetcher
User-agent: OAI-SearchBot
User-agent: PerplexityBot
User-agent: PetalBot
User-agent: Scrapy
User-agent: Sidetrade indexer bot
User-agent: Timpibot
User-agent: VelenPublicWebCrawler
User-agent: Webzio-Extended
User-agent: YouBot
User-agent: anthropic-ai
User-agent: cohere-ai
User-agent: facebookexternalhit
User-agent: iaskspider/2.0
User-agent: img2dataset
User-agent: omgili
User-agent: omgilibot
Disallow: /
Note : Le fichier robots.txt est basé sur une norme volontaire, et certains robots malveillants peuvent choisir de l'ignorer. Il est donc recommandé de combiner cette méthode avec d'autres approches.
Méthode 2 : Bloquer le Trafic depuis Votre Serveur Web
Pour une solution plus efficace, vous pouvez bloquer le trafic de ces robots au niveau du serveur Web en ajoutant des règles d'exclusion dans la configuration.
Pour NGINX :
- Ouvrez le fichier de configuration de votre site (généralement situé dans
/etc/nginx/sites-available/). - Ajoutez le code suivant dans le bloc
server:
if ($http_user_agent ~* (AI2Bot|Ai2Bot-Dolma|Amazonbot|Applebot|Applebot-Extended|Bytespider|CCBot|ChatGPT-User|Claude-Web|ClaudeBot|Diffbot|FacebookBot|FriendlyCrawler|GPTBot|Google-Extended|GoogleOther|GoogleOther-Image|GoogleOther-Video|ICC-Crawler|ImagesiftBot|Kangaroo Bot|Meta-ExternalAgent|Meta-ExternalFetcher|OAI-SearchBot|PerplexityBot|PetalBot|Scrapy|Sidetrade indexer bot|Timpibot|VelenPublicWebCrawler|Webzio-Extended|YouBot|anthropic-ai|cohere-ai|facebookexternalhit|iaskspider/2.0|img2dataset|omgili|omgilibot)) {
return 403;
}
- Redémarrez NGINX pour appliquer les modifications :
sudo systemctl restart nginx
Cette méthode retournera des codes d'erreur HTTP 403 à l'ensemble des robots se présentant avex le UserAgent présent dans la liste.
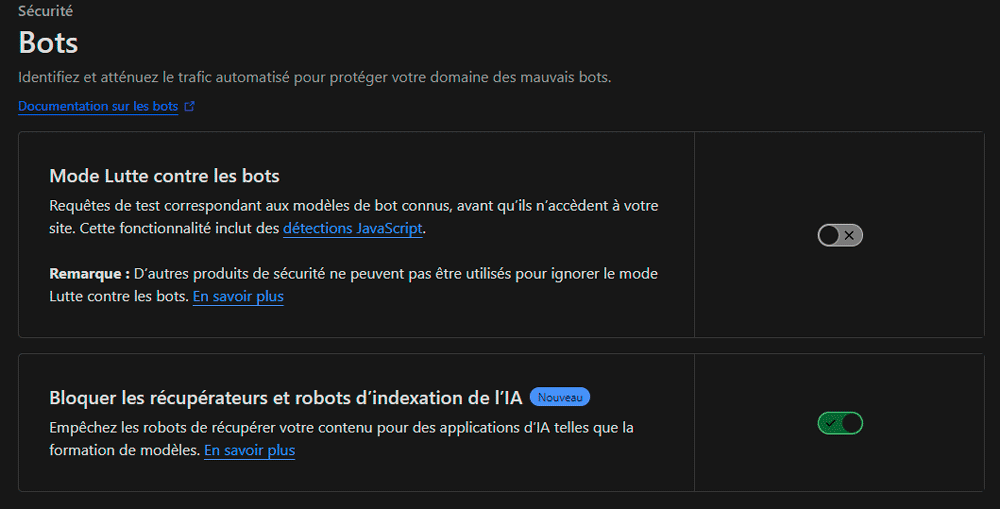
Méthode 3 : Utiliser un CDN/WAF comme Cloudflare
La plateforme Cloudflare offre une fonctionnalité intéressante permettant de bloquer les robots AI qui aspirent votre site. Celle-ci s'active en un seul clique depuis l'interface Web d'administration de Cloudflare.
Étapes :
- Connectez-vous à votre compte Cloudflare et sélectionnez votre site.
- Allez dans la section "Sécurité" puis "Bots".
- Activez l'option "Bloquer les robots AI".
Cette option est disponible sur toutes les offres Cloudflare, y compris l'offre gratuite.
Conclusion
Bien que ces méthodes puissent réduire l'accès des robots à votre site, il est important de comprendre qu'elles ne garantissent pas une protection totale. Certains robots peuvent masquer leur identité ou utiliser des techniques pour contourner ces blocages.

