
Comment installer le LLM Mistral sur son ordinateur ?
Je ne vous présente plus les LLMs, ou Large Language Model, une catégorie d'IA générative capable de produire du texte. Le LLM le plus connu étant GPT4, le LLM se cachant derrière l'interface de ChatGPT.
Dans cet article, je vous présente les LLM Opensource diffusées par la société Mistral.ai, mais aussi comment installer ces LLM sur votre ordinateur pour avoir l'équivalent d'un ChatGPT local.
LLM Propriétaires et LLM Opensource ?
Parmi les LLM, deux familles existent :
- Les LLM propriétaires.
- Les LLM OpenSource.
Parmi les LLM propriétaires, le plus connu actuellement est GPT 4 d'OpenAI, c'est aujourd'hui le LLM considéré comme le plus performant. Mais son usage nécessite un paiement au nombre d'appels réalisés et le nombre de tokens utilisés directement lié à la taille de contenus produits et quantité de texte en entrée. Il existe deux moyens d'exploiter les API d'OpenAI : soit au travers du playground d'OpenAI ou du playground d'Azure.
Une alternative existe: les LLM Opensource. Ces LLM sont distribués principalement au travers la plateforme Hugging Faces.
Ces modèles possèdent différentes tailles : 7B, 13B, 34B, 70B. Il s'agit du nombre de milliards de paramètres que le modèle possède.
Plus le modèle est grand, plus il nécessite des ressources GPU / RAM pour le faire tourner, mais plus il génère des réponses pertinentes aux questions qui lui sont posées.
Des mécanismes de "quantization" existent pour compresser ces modèles. Je ne détaillerai pas ce processus d'optimisation, vous pouvez trouver plus de détails sur la "quantization" sur cet article de Tensorops.
LLama2 : Le modèle Opensource le plus puissant jusqu'à l'arrivée de Mistral.ai
Jusqu'à peu de temps, le modèle Opensource le plus puissant était celui distribué par la société Meta, la maison mère de Facebook. Ce LLM est connu sous le nom de LLama et de CodeLLama pour le modèle entrainé pour produire du code.
Depuis peu, deux nouveaux LLM français très puissants ont vu le jour, il s'agit des LLM Mistral / Mixtral de la société Mistral.ai.
Cette startup française tout juste créée l'été dernier par deux anciens collaborateurs de Meta et un ancien de Google a réalisé l'une des plus grosses levées de fond connues. Partie avec 15k€, Mistral.ai est aujourd'hui valorisée à 2 milliards d'euros. La société Mistral.ai est devenue la licorne de l'IA générative en Europe.
Quels sont les prérequis pour installer Mistral ?
Si vous possédez un Mac Book récent ou un PC sous Linux ou sous Windows avec WSL2, vous pouvez installer le LLM de Mistral très facilement grâce à Ollama que je vous avais présenté dans un précédent article.
Attention, il vous faudra tout de même une carte graphique suffisement puissante pour faire fonctionner ce modèle.
Les LLM fonctionnent à base de vecteurs, de la même manière qu'un univers 3D au sein d'un jeu vidéo, c'est la raison pour laquelle les GPU des cartes graphiques sont optimisées pour les exécuter.
Comment installer le LLM de Mistral.ai ?
Le modèle 7B de Mistral fonctionne très bien sur un Mac Book M2 équipé de 16GB de RAM. Sur un PC Linux avec une carte NVIDIA de bonne facture et suffisamment de RAM, il doit pouvoir aussi très bien fonctionner tout comme sur WSL2 sous Windows.
Pour installer Mistral 7B, installer Ollama puis tapez tout simplement les commandes suivantes :
ollama pull mistral
ollama run mistral
Ce petit modèle 7B de Mistral dépasse Llama 2 13B et 34B sur beaucoup de benchmarks et approche CodeLLama 7B sur la production de code.
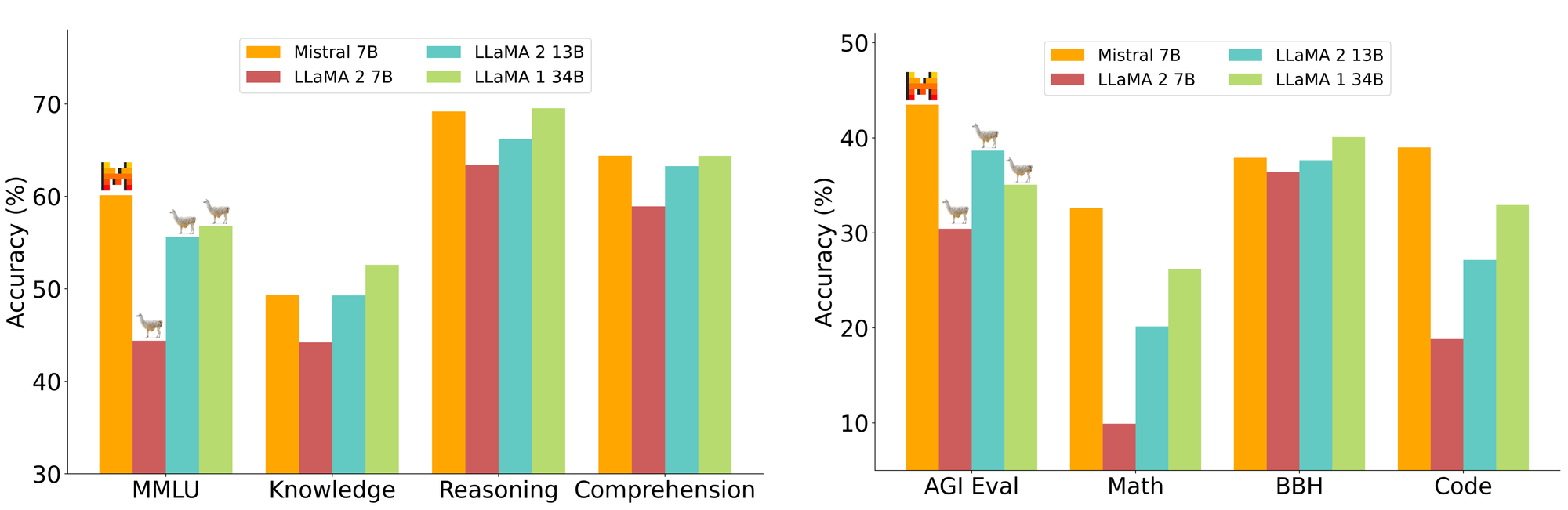
Concernant le modèle Mixtral 8x7B publié en décembre 2023, il consomme l'équivalent d'un modèle 14B alors qu'il en possède 56B.
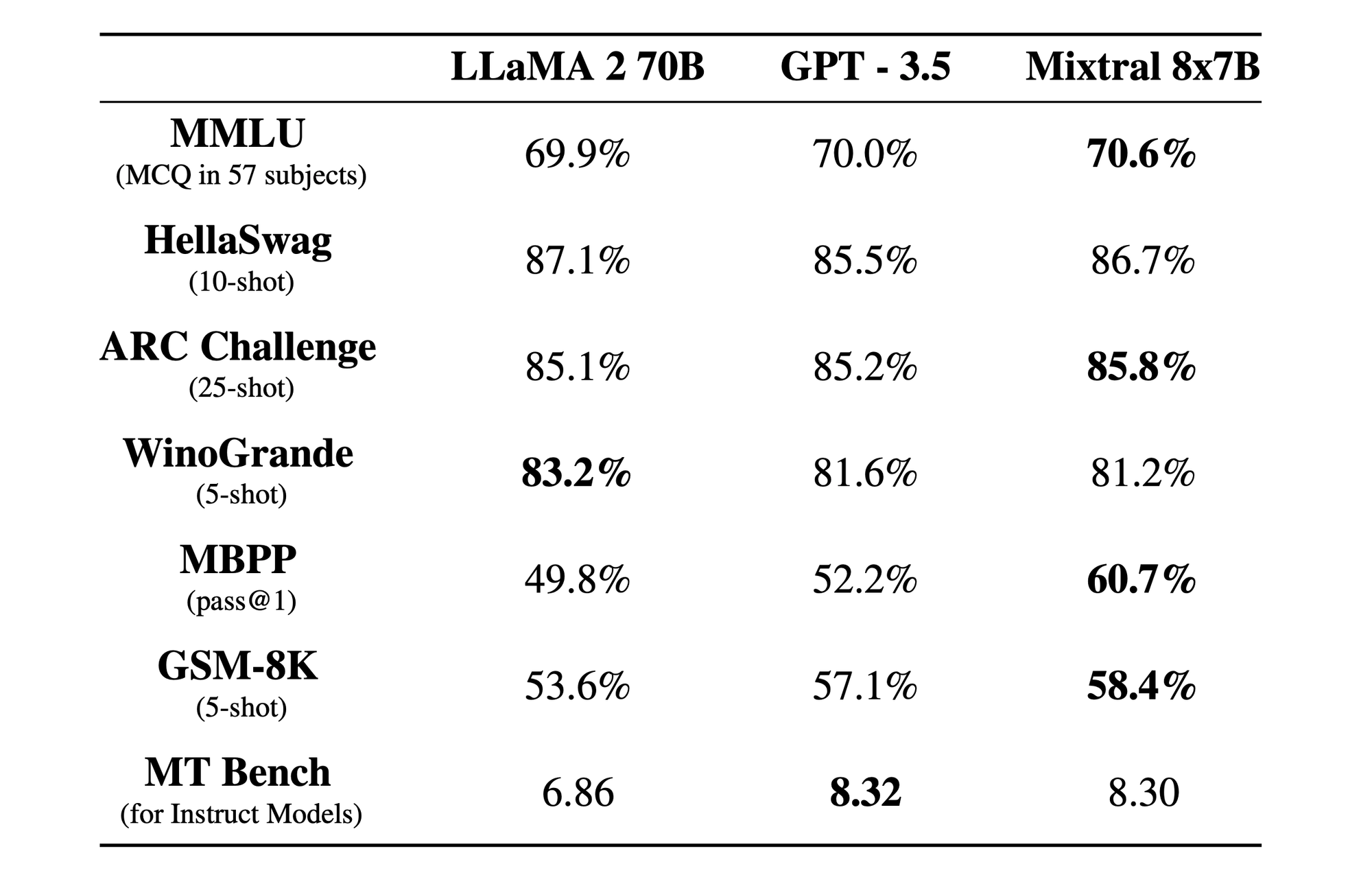
C'est à date modèle Opensource le plus puissant avec une licence très permissive qui existe dans le monde de l'Opensource. Ce modèle a cependant besoin d'un PC / Mac équipé de 64GB de RAM et d'une bonne carte graphique pour fonctionner correctement ...
ollama run mixtral
Comment utiliser le LLM Mistral avec Ollama ?
Ollama expose par défaut une API REST facile d'utilisation :
curl -X POST http://localhost:11434/api/generate -d '{
"model": "mistral",
"prompt":"Here is a story about llamas eating grass"
}'
Le port utilisé par défaut par Ollama est le 11434, mais il peut être adapté au besoin comme décrit dans mon article dédié à Ollama.
Cette API peut être intégrée par de nombreux logiciels :
- L'interface graphique Chatbot-Ollama permet de reproduire l'interface de ChatGPT localement sur son ordinateur.
- Le plugin Obsidian-Ollama permet d'intégrer Ollama directement sous forme de prompts dans l'outil de notes Obsidian.
- Le plugin LLama-Coder vous permet d'intégrer Ollama directement dans VSCode.
L'écosystème autour d'Ollama s'enrichit de jour en jour, il existe de nombreuses autres solutions d'intégration décrites sur la page de Github Ollama.
Comment intégrer le LLM Mistral dans un logiciel ?
Vous pouvez soit appeler l'API d'Ollama en direct ou passer par un SDK pour intégrer plus rapidement des appels à Ollama au sein d'un logiciel.
Ollama possède actuellement plusieurs SDK permettant de simplifier l'intégration d'un LLM au sein d'un logiciel :
En quelques lignes de code vous pouvez ainsi intégarir avec le LLM de Mistral :
import ollama from 'ollama'
const response = await ollama.chat({
model: 'mistral',
messages: [{ role: 'user', content: 'Pourquoi le ciel est bleu ?' }],
})
console.log(response.message.content)
Pour aller plus loin sur ces sujets d'IA générative, voici quelques articles connexes publiés sur ce blog :
- Comment utiliser ChatGPT pour analyser les commentaires d'une application mobile Android ?
- 49 exemples de cas d'usage pour découvrir GPT3
- GitHub Copilot : Synthèse de l'IA pour les développeurs
- Ollama : Installez LLama 2 et Code LLama en quelques secondes !
Source des Benchmarks : Mistral.ai
À lire aussi : Google Flow (VEO3)

