
Claude Code trop cher ? 8 astuces pour optimiser votre consommation de tokens
Depuis que j'ai intégré Claude Code dans mon workflow de développement sur mes projets personnels et réalisé des expérimentations en entreprise, une chose m'a frappé : la consommation de tokens est vertigineuse. Sur un usage entreprise de Claude Code, la facturation se fait au token et la facture peut très vite devenir salée.
On commence par quelques sessions de test, et trois semaines plus tard on réalise qu'une seule journée intensive sur un gros projet peut engloutir l'équivalent d'une semaine de budget en tokens d'entrée avec une facture de plusieurs centaines d'euros.
Dans les déploiements d'entreprise, Anthropic indique un coût moyen d'environ 13$ par développeur par jour actif, soit 150$ à 250$ par développeur par mois, avec 90% des utilisateurs restant sous 30$/jour[1]. Dans la réalité, un usage mal maîtrisé et non optimisé peut très vite atteindre les 200$/jour.
J'ai creusé le sujet en long et en large (serveurs MCP, variables d'environnement, configuration CLAUDE.md) et voici une liste d'astuces pour réduire les tokens Claude Code sans sacrifier la qualité du résultat.
Ces astuces proviennent en partie de posts que j'ai capturés sur mon fil de lecture LinkedIn. Un énorme merci à tous les développeurs qui partagent leurs retours d'expérience sur la toile.
La réduction des tokens par 5 est possible sur des projets ne respectant aucune de ces bonnes pratiques.
💡 Comprendre pourquoi Claude Code consomme autant de tokens
Avant d'optimiser quoi que ce soit, il faut comprendre le problème de fond. Claude Code adopte naturellement une stratégie d'exploration aveugle : pour diagnostiquer un bug ou implémenter une feature, il parcourt les fichiers un à un, charge le README, les fichiers de config, les dépendances, et reconstruit mentalement l'architecture du projet à chaque session.
Sur un petit projet perso, c'est négligeable. Sur une codebase de 50 000 lignes, Claude peut lire 10 à 20 fichiers complets avant d'écrire la moindre ligne de code. Des dizaines de milliers de tokens d'entrée, par message, payés au prix fort.
C'est ce poste-là qu'il faut attaquer en priorité pour avoir un impact positif sur sa consommation.
💰 Tarifs des Modèles Claude (par million de tokens)
Pour vous donner une idée des coûts des tokens, voici les tarifs actuels pour les modèles utilisés par Claude Code (via l'API Anthropic).
Les modèles sont en constante évolution, il est probable que ce tableau soit très vite obsolète.
| Modèle | Input | Output | Cache (lecture) | Usage type dans Claude Code |
|---|---|---|---|---|
| Claude Sonnet 4.6 | 3,00 $ | 15,00 $ | 0,30 $ | Standard (équilibre vitesse/intelligence) |
| Claude Opus 4.6 | 5,00 $ | 25,00 $ | 0,50 $ | Tâches complexes d'architecture |
| Claude Haiku 4.5 | 1,00 $ | 5,00 $ | 0,10 $ | Opérations légères et scripts simples |
Prix en USD par million de tokens (MTok). Le cache lecture correspond à 10% du prix input standard.
Les API de Claude Code peuvent être achetées directement auprès d'Anthropic mais aussi auprès de plusieurs hyperscalers : AWS Bedrock, Google Vertex AI, Microsoft Foundry. Le tarif de vente du token est le même entre l'ensemble de ces acteurs mais il ne semble pas possible d'obtenir des métriques de coûts d'usage sur ces hyperscalers sans la mise en œuvre de LiteLLM[2].
⚡Optimisation des coûts avec le "Prompt Caching"
Claude Code s'appuie nativement sur le Prompt Caching d'Anthropic, et c'est un levier de réduction des coûts massif si on comprend comment il fonctionne et ses limites actuelles.
Le principe : la première fois que Claude traite un contexte (votre code, vos instructions, l'historique de la session), il le stocke dans un cache coté serveur. Les requêtes suivantes qui retrouvent ce même contexte intact le lisent depuis le cache plutôt que de le retraiter intégralement.
La structure de tarification sur Sonnet 4.6 (3,00 $/MTok en input standard) :
- Écriture dans le cache (TTL 5 min) : +25% du prix input standard, soit 3,75 $/MTok
- Lecture du cache (cache hit) : 10% du prix input standard, soit 0,30 $/MTok — une réduction de 90%
Exemple concret sur un projet dont le contexte pèse 100 000 tokens (8 000 à 12 000 lignes de code) :
- La première requête écrit dans le cache : 0,375 $
- Les requêtes suivantes lisent depuis le cache : 0,03 $ chacune
Le gain est réel et se ressent vite sur les sessions longues.
Attention toutefois au changement de TTL d'avril 2026[3]. C'est le point que beaucoup de développeurs ont raté et qui explique pourquoi pas mal d'utilisateurs voient leur facture grimper sans comprendre pourquoi.
Début avril 2026, Anthropic a réduit le TTL par défaut du cache de 1 heure à 5 minutes dans Claude Code, sans aucune annonce claire auprès de ses utilisateurs malgré que l'information soit bien décrite dans sa documentation en ligne.
Résultat, si votre session dépasse 5 minutes d'inactivité, le prochain message repart d'un contexte complet, non caché, au plein tarif.
Pour retrouver le comportement à 1 heure, il faut activer manuellement la variable ENABLE_PROMPT_CACHING_1H[4] dans votre environnement. Pour les sessions de travail longues avec des pauses, c'est quasi indispensable.
Ce n'est pas neutre, cette option cachée qui permet d'allonger par défaut la durée du cache semble avoir un impact sur le tarif de mise en cache. Un coefficient x2 est à appliquer au lieu du x1.25 sur le cache de 5 minutes[4:1].
📦 Utilisez les plugins de Code Intelligence
Pour simplifier la compréhension et la lecture du code en local, des plugins LSP sont mis à disposition par Anthropic afin d'aider l'agent de code à parcourir la structure du code sans utiliser la commande "grep".
Des plugins LSP existent pour la majorité des langages : C, Java, Rust, Python, Go... vous pouvez aussi créer votre propre plugin si vous utilisez des langages maison.
🧠 Understand-Anything : transformer votre codebase en base de données interrogeable
Le plugin Understand-Anything est de loin l'outil le plus impactant que j'ai testé pour réduire les tokens Claude Code.
Son principe est simple : au lieu de laisser Claude lire les fichiers à la volée, Understand-Anything indexe votre projet en amont et construit un graphe de connaissance local, un réseau de nœuds représentant vos fichiers, fonctions, classes et leurs relations. Claude n'interroge ensuite que les nœuds pertinents via une recherche sémantique, sans charger de fichiers entiers dans le contexte.
Plus concrètement :
- L'analyse de la structure du projet se fait une fois, en local. Zéro token consommé à l'indexation.
- Claude obtient des réponses ciblées sur la structure du projet sans lire le code ligne par ligne.
- Fini les relectures du README à chaque nouveau tour de conversation.
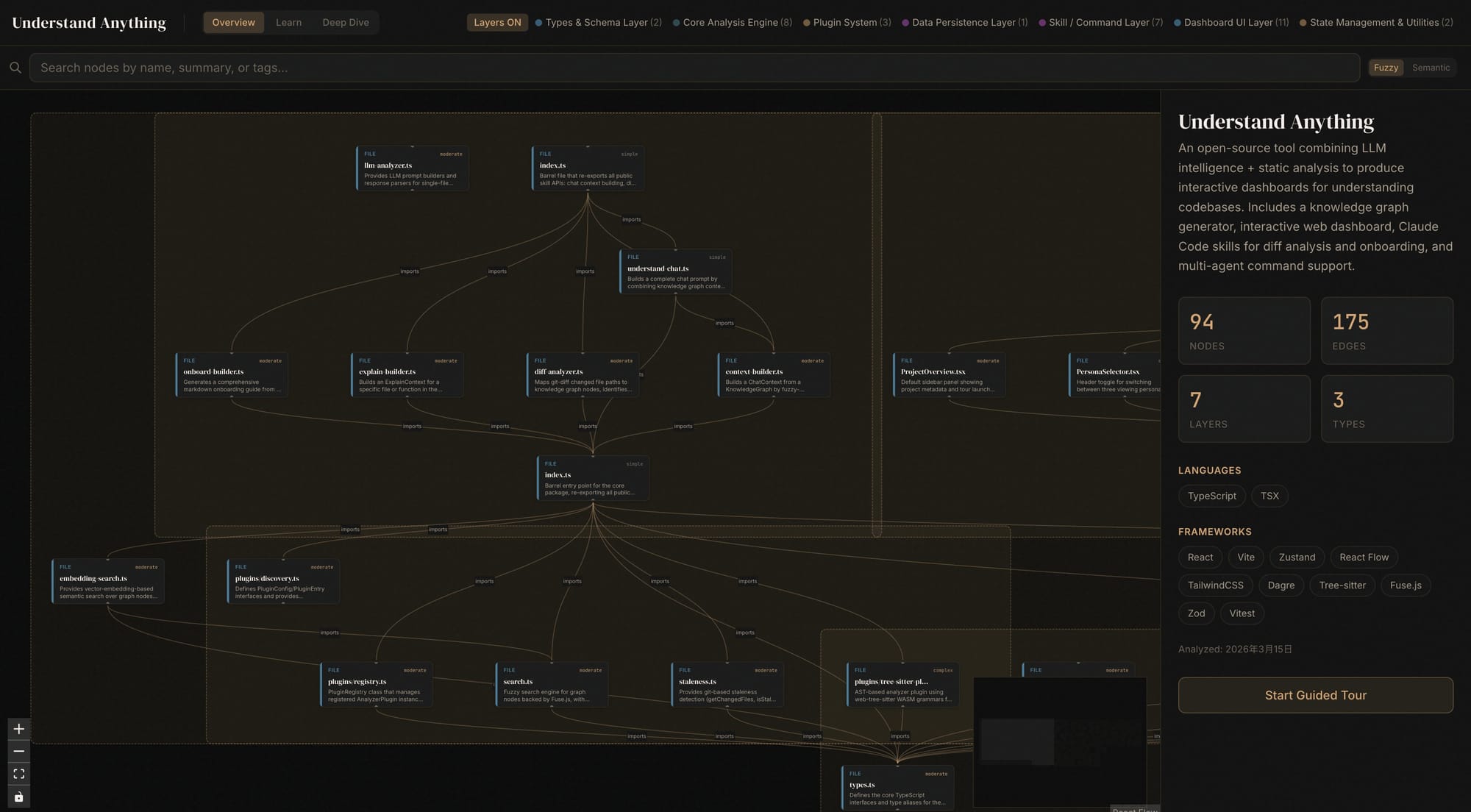
Pour un projet de grande taille, c'est le levier numéro un. Si vous ne deviez installer qu'un seul plugin pour optimiser votre consommation, ce serait celui-là.
🔎 Les serveurs MCP de recherche et d'indexation
Deux autres serveurs complètent bien le MCP Understand-Anything pour réduire les tokens Claude Code :
Everything MCP : quand Claude cherche un fichier, sa réaction par défaut est ls -R ou grep sur le répertoire entier. Des commandes qui renvoient des listes massives de chemins, même inutiles. Everything MCP intercepte ces requêtes et ne retourne que les chemins strictement pertinents. Le gain sur les tokens de sortie est visible dès le premier jour.
Memory MCP : au fil d'une session longue, le contexte s'alourdit sérieusement. Historique des échanges, raisonnements intermédiaires, décisions prises en cours de route. Chaque nouveau message oblige Claude à relire tout cela pour retrouver une info discutée vingt messages plus tôt. Memory MCP stocke faits et décisions dans un index local persistent, accessible directement. Sur des sessions de débogage qui durent parfois 3 à 4 heures, l'économie devient très concrète.
📦 Les outils de compression de contexte (PreToolUse Hooks)
Des outils comme RTK (Repo Tool Kit) fonctionnent comme des hooks qui s'intercalent entre Claude et votre système de fichiers. Ils interceptent les commandes de lecture (cat, git diff, git log) et renvoient une version compressée du résultat plutôt que le contenu brut.
Exemple : au lieu d'un diff de 200 lignes, Claude reçoit uniquement les signatures de fonctions modifiées et un résumé des changements. Pour des sessions de code review sur des PRs larges, c'est une solution très intéressante.
⚙️ Les réglages à activer immédiatement dans Claude Code
Sans installer quoi que ce soit, ces réglages réduisent la consommation de façon immédiate.
/effort low : réduit le nombre d'appels d'outils et la longueur des réponses pour les tâches simples. Je l'active pour tout ce qui ne nécessite pas d'analyse approfondie : renommage de variables, ajout de commentaires, corrections de typos.
/compact : résume la conversation en cours pour vider le contexte accumulé. Je m'en sers avant de passer à une nouvelle tâche dans une session existante. C'est le geste le plus simple et le plus sous-estimé pour réduire les tokens Claude Code.
Un CLAUDE.md minimal : si votre fichier CLAUDE.md fait 500 lignes, vous payez ces 500 lignes à chaque message de la session, sans exception. La règle que j'applique : ne garder dans CLAUDE.md que les instructions absolument universelles. Tout le reste part dans des Skills (scripts ou sous-fichiers) qui ne se chargent que lorsque Claude en a explicitement besoin.
📉 Estimez et suivez votre consommation de tokens
Face aux coûts importants de certaines tâches, des outils open source commencent à apparaître pour vous aider à estimer une tâche avant de la lancer.
C'est par exemple le cas de l'outil Tarmac de CodeSarthak.
Pour suivre votre consommation, les outils CCUsage et Claude Code Usage Monitor peuvent vous aider à y voir plus clair.
☑️ En synthèse
Si vous travaillez sur un projet de taille réelle, commencez par Understand-Anything, le refactoring de votre CLAUDE.md et l'activation des plugins LSP de Code Intelligence. Ces actions combinées font la majorité du travail.
Avec les évolutions tarifaires récemment annoncées par les fournisseurs de solutions de Coding Agent, l’optimisation de la consommation de tokens devient un enjeu stratégique pour garantir la viabilité économique et les économies d’échelle de ces plateformes à long terme.
Dans ce contexte, l’utilisation de modèles raisonnés exécutés localement avec Ollama pourrait représenter une alternative particulièrement pertinente pour certains cas d’usage, notamment afin de réduire significativement les coûts d’inférence et la dépendance aux API cloud.
Vous avez d'autres astuces pour réduire les tokens Claude Code ? Laissez un commentaire en dessous de cet article et venez en discuter sur le Discord Geeek, un canal dédié au Coding est ouvert à tous.

