LLMFit : Quel LLM faire tourner sur votre ordinateur ?
Vous voulez faire tourner un LLM sur votre PC ou votre Mac mais vous ne savez pas quel modèle choisir entre Llama, Mistral, Qwen ou DeepSeek ? LLMFit analyse votre hardware en quelques secondes et vous recommande les modèles les plus adaptés.
Vous le savez déjà probablement, les LLMs de petite et moyenne taille peuvent fonctionner sur nos ordinateurs personnels. C'est notamment possible grâce à l'outil Ollama que je vous avais partagé il y a déjà 3 ans. Mais une fois Ollama installé, la vraie question se pose : quel modèle choisir ?
Faire fonctionner un LLM de coding localement vous permet de construire votre propre assistant de coding, d'autant plus l'annonce de Github Copilot qui supporte désormais des modèles en mode offline.
Quels modèles LLM choisir selon votre configuration ?
C'est le problème que rencontre tout le monde : on entend parler d'un nouveau modèle, on le télécharge, on attend 20 minutes… et on découvre qu'il ne tient pas en VRAM ou qu'il tourne à 3 tokens par seconde. Résultat : une après-midi perdue en tâtonnements.
C'est exactement ce problème que résout LLMFit, un outil open source en ligne de commande écrit en Rust. Il détecte automatiquement votre configuration matérielle (RAM, CPU, GPU/VRAM, support CUDA/Metal/ROCm…) et vous indique en quelques secondes quels modèles peuvent réellement tourner correctement sur votre machine — avant même de télécharger quoi que ce soit.
Mon retour d'expérience
Voici un exemple concret d'analyse de LLMFit. J'ai testé sur mon MacBook Pro M2 avec 32 Go et voici ce qu'il me recommande concernant les coding LLMs :
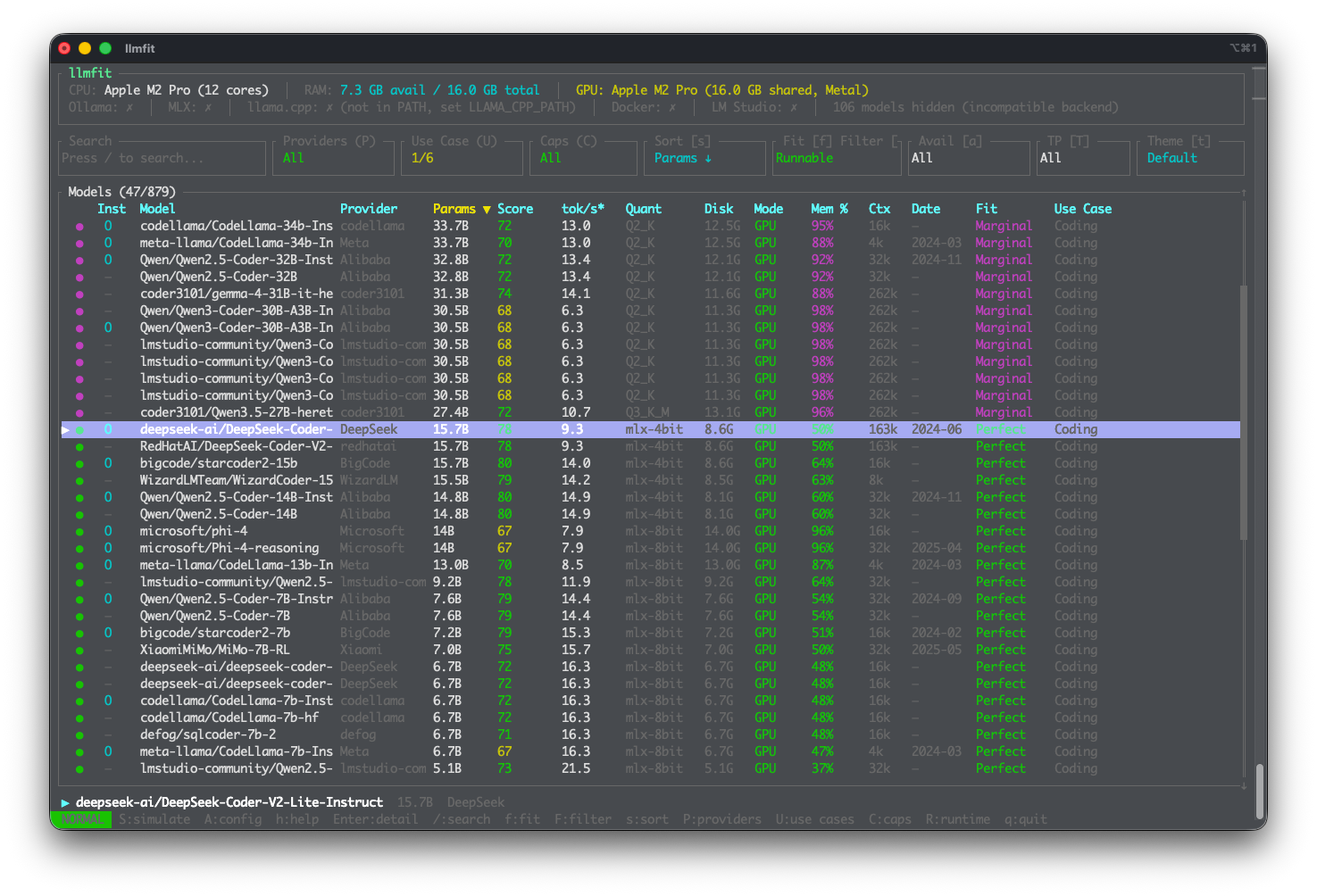
LLMFit couvre aujourd'hui plus de 157 modèles provenant de 30 fournisseurs différents (Meta, Mistral, Google, etc.) et les classe selon quatre dimensions :
- Qualité du modèle
- Vitesse d'inférence estimée (en tokens/seconde)
- Compatibilité mémoire (GPU, CPU+GPU, CPU seul)
- Longueur de contexte supportée
Les modèles listés par LLMFit sont disponibles sur Hugging Face.
Il gère également la sélection automatique de la meilleure quantization possible (de Q8_0 à Q2_K), les architectures MoE, et les setups multi-GPU. Et bien sûr, il s'intègre nativement avec Ollama, llama.cpp, MLX et LM Studio.
L'interface est un TUI interactif (navigable au clavier) avec filtres par cas d'usage : Chat, Coding, Reasoning, Multimodal, Embedding… Un mode --cli classique et une sortie --json sont aussi disponibles pour l'automatisation.
Quel modèle pour quelle config ?
Voici un tableau synthètique des modèles les plus connus classés en fonction de l'espace RAM/VRAM disponible.
| RAM / VRAM disponible | Modèles recommandés | Usage |
|---|---|---|
| 8 Go | Llama 3.2 3B, Phi-3 Mini | Chat basique, résumés |
| 16 Go | Mistral 7B, Llama 3.1 8B | Chat avancé, code simple |
| 24 Go | Qwen 14B, Gemma 2 27B (Q4) | Raisonnement, coding |
| 48 Go+ | Llama 3.3 70B (Q4), Mixtral 8x7B | Tâches complexes |
Quel matériel pour faire tourner un LLM spécifique ?
Imaginons que vous ayez repéré un modèle précis sur Hugging Face et que vous souhaitiez savoir quelle configuration matérielle serait nécessaire pour le faire tourner correctement. C'est tout l'intérêt du mode plan de LLMFit : au lieu de scanner votre machine pour recommander des modèles, il fait l'inverse — vous lui donnez un modèle, il vous indique le hardware idéal.
La commande de base ressemble à ceci :
llmfit plan "Qwen/Qwen3-4B-MLX-4bit" --context 8192
LLMFit vous affiche alors la quantité de VRAM ou de RAM nécessaire, la quantization optimale, ainsi qu'une estimation de la vitesse (en tokens/seconde) selon les différents types de backends (CUDA, Metal, ROCm, CPU...).
Spécifier une quantization précise
Si vous avez déjà une idée de la quantization que vous souhaitez utiliser, vous pouvez la fixer :
llmfit plan "Qwen/Qwen3-4B-MLX-4bit" --context 8192 --quant mlx-4bit
Cibler une vitesse minimale
Autre option très pratique : définir une vitesse cible en tokens/seconde. LLMFit vous indiquera alors quel matériel permet d'atteindre cet objectif :
llmfit plan "Qwen/Qwen3-4B-MLX-4bit" --context 8192 --target-tps 25 --json
Parfait par exemple pour vérifier qu'un modèle tournera à une vitesse confortable avant d'investir dans un nouveau GPU ou un Mac équipé de plus de mémoire unifiée.
À quoi cela sert concrètement ?
Ce mode est particulièrement utile dans plusieurs cas d'usage :
- Avant un achat hardware : vérifier qu'un RTX 4090 ou un Mac Studio M3 Max suffira pour le modèle que vous visez
- Dimensionner un serveur : calibrer précisément un VPS GPU ou une instance cloud avant de louer
- Comparer plusieurs modèles : voir lequel passe le mieux sur la config que vous comptez monter
- Éviter les mauvaises surprises : ne plus télécharger 40 Go de poids pour découvrir que ça rame à 3 tokens/seconde
Couplé au mode simulation (touche S dans le TUI) qui permet de tester des configurations hypothétiques directement depuis l'interface, le mode plan transforme LLMFit en véritable outil d'aide à la décision pour tout passionné d'IA locale.
Comment installer LLMFit sur Windows, macOS et Linux
Windows (via Scoop)
scoop install llmfit
macOS / Linux (via Homebrew)
brew install llmfit
Installation rapide (curl)
curl -fsSL https://llmfit.axjns.dev/install.sh | sh
# Installation locale (sans sudo)
curl -fsSL https://llmfit.axjns.dev/install.sh | sh -s -- --local
Docker / Podman
docker run ghcr.io/alexsjones/llmfit
# Exemple : recommandations pour le coding, filtrées avec jq
podman run ghcr.io/alexsjones/llmfit recommend --use-case coding | jq '.models[].name'
Depuis les sources (Rust requis)
git clone https://github.com/AlexsJones/llmfit.git
cd llmfit
cargo build --release
Quelques commandes utiles
Une fois installé, voici les commandes essentielles :
llmfit # Lance le TUI interactif
llmfit system # Affiche votre configuration matérielle
llmfit fit --perfect -n 5 # Top 5 des modèles parfaitement compatibles
llmfit recommend --use-case coding # Recommandations par cas d'usage
llmfit search "qwen 8b" # Recherche un modèle spécifique
FAQ
LLMFit est-il gratuit ?
Oui, LLMFit est entièrement open source (licence MIT) et gratuit.
Faut-il un GPU pour utiliser LLMFit ?
Non, LLMFit fonctionne aussi sur CPU uniquement...
Quelle différence entre LLMFit et Ollama ?
Ollama fait tourner les modèles, LLMFit vous dit lesquels choisir...
Combien de RAM pour faire tourner un LLM localement ?
Comptez minimum 8 Go pour un modèle 3B, 16 Go pour 7B...
Conclusion
LLMFit est l'outil qui manquait à l'écosystème des LLMs locaux. Simple, rapide, et construit en Rust, il évite les heures de tâtonnements en vous donnant une réponse claire : voici ce que votre machine peut faire tourner, et voici le meilleur modèle pour chaque usage.
Pour en savoir plus, rendez-vous sur llmfit.org ou directement sur le dépôt GitHub du projet (qui possède déjà déjà plus de 24k ⭐).
Cet article vous a intéressé ? N'hésitez pas à vous abonner à notre newsletter ou au flux RSS. Le serveur Discord Geeek reste ouvert à tous les lecteurs, n'hésitez pas à passer.
À lire aussi : ChatGPT supporte les serveurs MCP ! · Hyprnote : l’alternative 100% locale pour résumer vos réunions Zoom, Teams ou Meet

